# 引言
在现代软件架构中,尤其是在微服务和 Serverless 计算领域,应用的快速启动和高效资源利用变得至关重要。Java 作为企业级应用开发的首选语言,尽管拥有庞大的生态和丰富的开发工具,但在启动速度方面始终面临挑战。与原生编译语言和部分脚本语言相比,Java 应用在启动过程中存在明显的性能差距。“冷启动”,即应用实例首次启动,或是从休眠状态唤醒时,系统需要经历复杂的初始化过程,这不仅会导致显著的时间延迟,还会引发资源消耗的峰值。
那么,为什么 Java 应用的冷启动会比较慢呢?这并不仅仅是一个单一的步骤,而是涉及多个阶段,通常可以分为“JVM 启动”、“应用启动”和“应用预热”三个主要过程:
- JVM 启动 (JVM Start - 相对较快): 这个阶段主要是 Java 虚拟机(JVM)自身的初始化,包括加载核心库、初始化内存管理(如堆、垃圾收集器)、设置内部数据结构以及进行一些早期的基础优化。
- 应用启动 (Application Start - 需要一些时间): 在 JVM 准备好之后,开始加载应用程序自身的类和所有依赖库。这是一个密集的过程,涉及查找、验证和解析大量的类。紧接着,应用框架(如 Spring Boot)会执行其初始化逻辑:扫描组件、解析配置、构建依赖注入容器、初始化线程池、建立数据库连接等。这个阶段完成后,应用通常可以处理第一个请求,因此这个阶段的耗时常被称为“首次响应时间(Time to first response)”。
- 应用预热 (Application Warmup - 需要较长时间): 即使应用能够响应第一个请求,它通常还远未达到最佳性能。Java 的高性能依赖于即时编译器 JIT(Just-In-Time Compiler)。
JIT会在运行时监控代码执行情况,识别“热点(hotspot)”代码(频繁执行的方法),并将其编译成本地机器码以提升效率。这个编译过程是分层的(例如,从解释执行到 C1 编译,再到更深层次优化的 C2 编译),需要时间和实际的业务负载来触发和完成。此外,还可能涉及缓存的填充、连接池的预热等。只有在JIT完成了关键代码的编译优化,并且应用处理了一定量的请求后,才能达到其峰值性能。这个过程被称为“应用预热”。期间还可能伴随着编译/反优化(Deoptimisations)和垃圾回收暂停(Garbage Collector pauses)带来的性能波动。
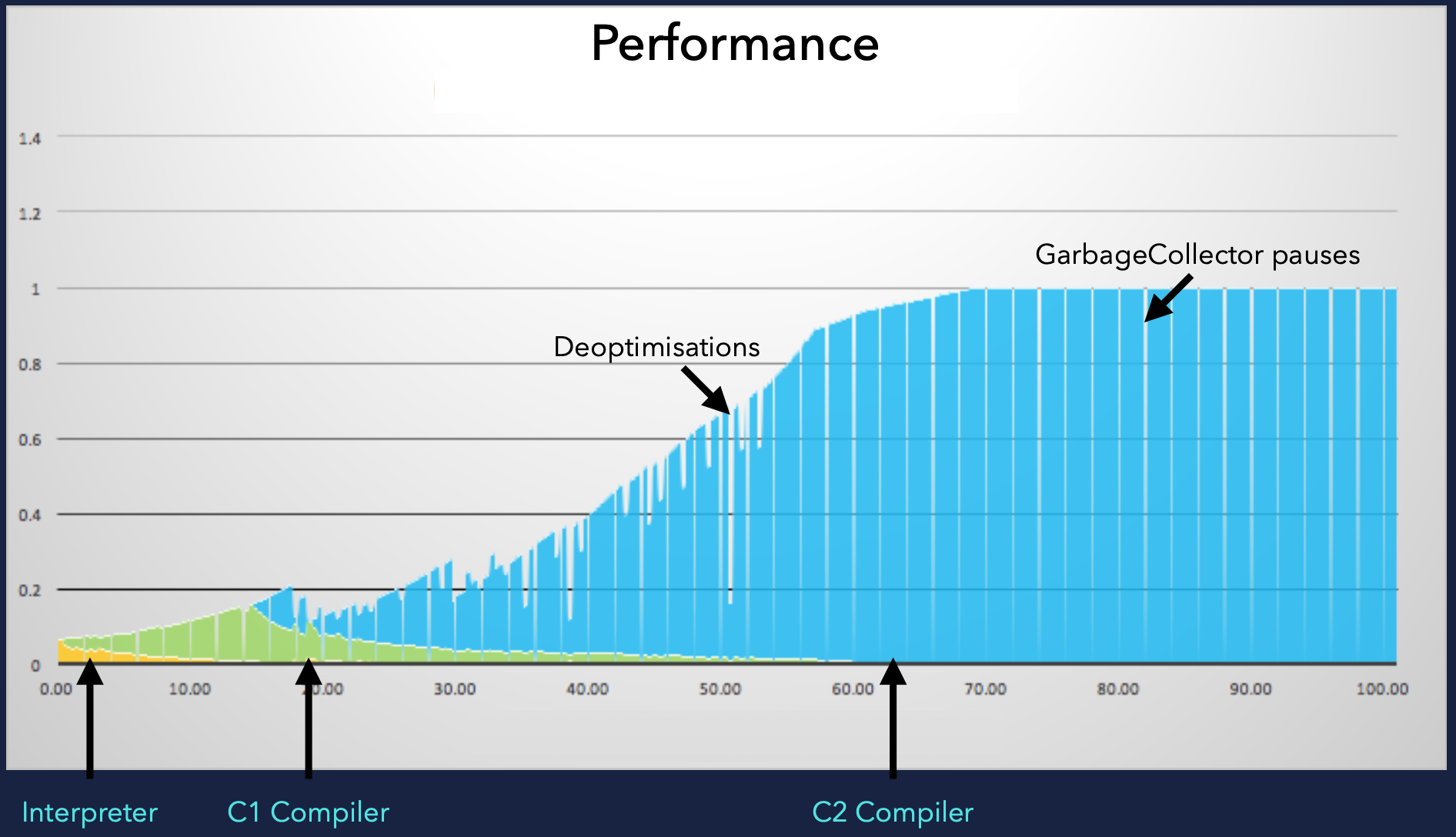
这三个阶段叠加起来,特别是“应用启动”和“应用预热”阶段的耗时,导致了 Java 应用的冷启动时间较长,并且需要一段时间才能达到理想的处理能力。对于需要快速响应和弹性伸缩的微服务和 Serverless 场景,这种延迟是亟待解决的痛点。缓慢的启动影响扩容效率,而漫长的预热则意味着在达到峰值性能前,应用的处理能力受限且响应时间不稳定。
正是为了解决这一痛点,CRaC (Coordinated Restore at Checkpoint) 技术应运而生。它并非逐一优化上述启动和预热的各个环节,而是另辟蹊径:通过在应用程序完成初始化并充分“预热”达到接近峰值性能状态后,创建一个包含整个 JVM 进程状态的“快照”(Checkpoint),并在需要新实例时直接从这个快照快速“恢复”(Restore)。这种方式几乎完全绕过了耗时的“应用启动”和“应用预热”过程,有望将启动并达到高性能状态的时间缩短到毫秒级别。
本文旨在深入探讨 CRaC 技术,从其核心原理、与 AOT 等技术的对比、具体实现机制、实际使用方法,到其在不同场景下的应用和生态发展,全面解析这一旨在革新 Java 启动与预热性能的前沿技术。
# 一、CRaC 概述:告别漫长等待
# 什么是 CRaC?
CRaC(Coordinated Restore at Checkpoint)是 OpenJDK 的一个项目,旨在通过创新的方式显著缩短 Java 应用的启动时间。CRaC 的核心思想是:在应用程序运行到某个理想状态(通常是初始化完成并经过预热后)时,创建一个包含整个 JVM 进程内存状态(包括堆内存、已加载类、已编译代码、线程状态等)的快照,即“检查点”(Checkpoint),并将其持久化。当需要启动新实例时,不再执行传统的启动流程,而是直接从该快照“恢复”(Restore)JVM 状态。这个恢复过程跳过了大部分 JVM 初始化、类加载和应用初始化步骤,从而极大地加快了启动速度。其中,“协调”(Coordinated)是关键,意味着 JVM 需要与应用程序通过特定 API 进行交互,以确保在创建检查点和恢复时,外部资源(如文件句柄、网络连接)能够被妥善地关闭和重新建立。
# CRaC 的核心优势
- 极速启动: 这是 CRaC 最显著的优势。传统 Java 应用启动可能需要数秒甚至数十秒,而使用 CRaC 从快照恢复,可以将启动时间缩短到数百毫秒甚至更短,接近原生应用的启动速度。因为它直接跳过了 JVM 初始化、类加载、应用初始化和大部分 JIT 预热等耗时环节。
- 即时峰值性能: 由于 Checkpoint 通常是在应用已经完成 JIT 编译优化和预热后创建的,因此恢复后的实例几乎可以立即达到其最佳性能状态,避免了传统启动后漫长的“预热”等待期。这对于需要快速响应请求的场景(如 Serverless)尤其重要。
- 潜在的资源节约: 传统的启动和预热过程通常是 CPU 密集型的。通过 CRaC,这些密集的计算被转移到了 Checkpoint 创建阶段(通常在非高峰时段或构建过程中完成),而在实际需要启动新实例时(如服务扩容或函数调用时),资源消耗显著降低,有助于提高资源利用率和降低成本。
# CRaC 的关键概念
- Checkpoint (检查点): 指创建 JVM 进程状态快照的操作,以及生成的包含该状态的持久化文件或镜像。
- Restore (恢复): 指从一个已存在的 Checkpoint 快速加载 JVM 状态,启动一个新 JVM 实例的过程。
- Coordination (协调): 指 JVM 与应用程序之间通过特定 API(
jdk.crac包)进行的交互。应用程序需要实现接口来管理其资源(如关闭网络连接、文件句柄等)以确保 Checkpoint 的一致性,并在 Restore 后重新建立这些资源。这是保证恢复后的应用能正常工作的关键。
# 二、CRaC vs. AOT:启动优化的两条路径
为了解决 Java 启动慢和预热长的问题,业界探索了不同的优化路径。除了 CRaC,另一种广受关注的技术是 AOT(Ahead-of-Time)编译,特别是以 GraalVM Native Image 为代表的实现。两者都旨在缩短启动时间,但它们的原理和特性却大相径庭。
# AOT 技术简介
AOT 编译的核心思想是,在应用程序运行之前,就将其 Java 字节码直接编译成本地机器码,生成一个独立的可执行文件(例如 GraalVM Native Image)。这样做带来的主要优势是:
- 无需解释字节码 (No interpreting bytecodes): 启动时直接执行本地代码,跳过了 JVM 解释执行字节码的阶段。
- 无需运行时编译 (No runtime compilation of code): 消除了 JIT 在运行时编译代码带来的 CPU 开销。
- 启动即全速 (Start at ‘full speed’, straight away): 应用启动后几乎立刻就能达到其稳定性能状态(尽管这个稳定状态可能不是最高峰值),大大缩短了“首次响应时间”。
- 更小的内存占用: 生成的本地可执行文件不包含 JVM 和 JIT 编译器,运行时内存占用通常显著低于标准 JVM。
# AOT 的挑战与局限
然而,AOT 并非完美无缺,它也面临一些固有的挑战:
-
静态编译的本质 (AOT is, by definition, static) AOT 的本质是代码在运行之前就被编译。这意味着编译器无法获知代码在运行时的实际行为 。AOT 不能像 JIT 那样根据运行时的真实负载和代码路径进行深度优化。
-
Profile Guided Optimization (PGO) 的引入与局限 为了缓解静态编译缺乏运行时信息的缺点,AOT 可以结合 Profile Guided Optimization (PGO)。
PGO 的基本思路是:先通过插桩(Instrumentation)或者采样的方式运行一次程序,收集代码执行频率、分支跳转等信息,生成 Profile 数据(例如 GCC 中使用 -fprofile-generate 编译运行以生成 profile 文件);然后,在最终编译时将这些 Profile 数据提供给编译器(例如 GCC 使用 -fprofile-use),让编译器根据这些“先验知识”进行更针对性的优化,比如更好地安排代码布局、更准确地进行分支预测、更有效地进行函数内联等。
然而,对于 AOT 编译来说,PGO 只能部分缓解问题 (can partially help)。因为收集到的 Profile 数据可能只代表了某一次或某几次运行的特征,无法完全覆盖所有可能的运行时场景和输入数据。因此,基于 PGO 的 AOT 优化效果通常仍难以媲美 JIT 的动态优化能力。
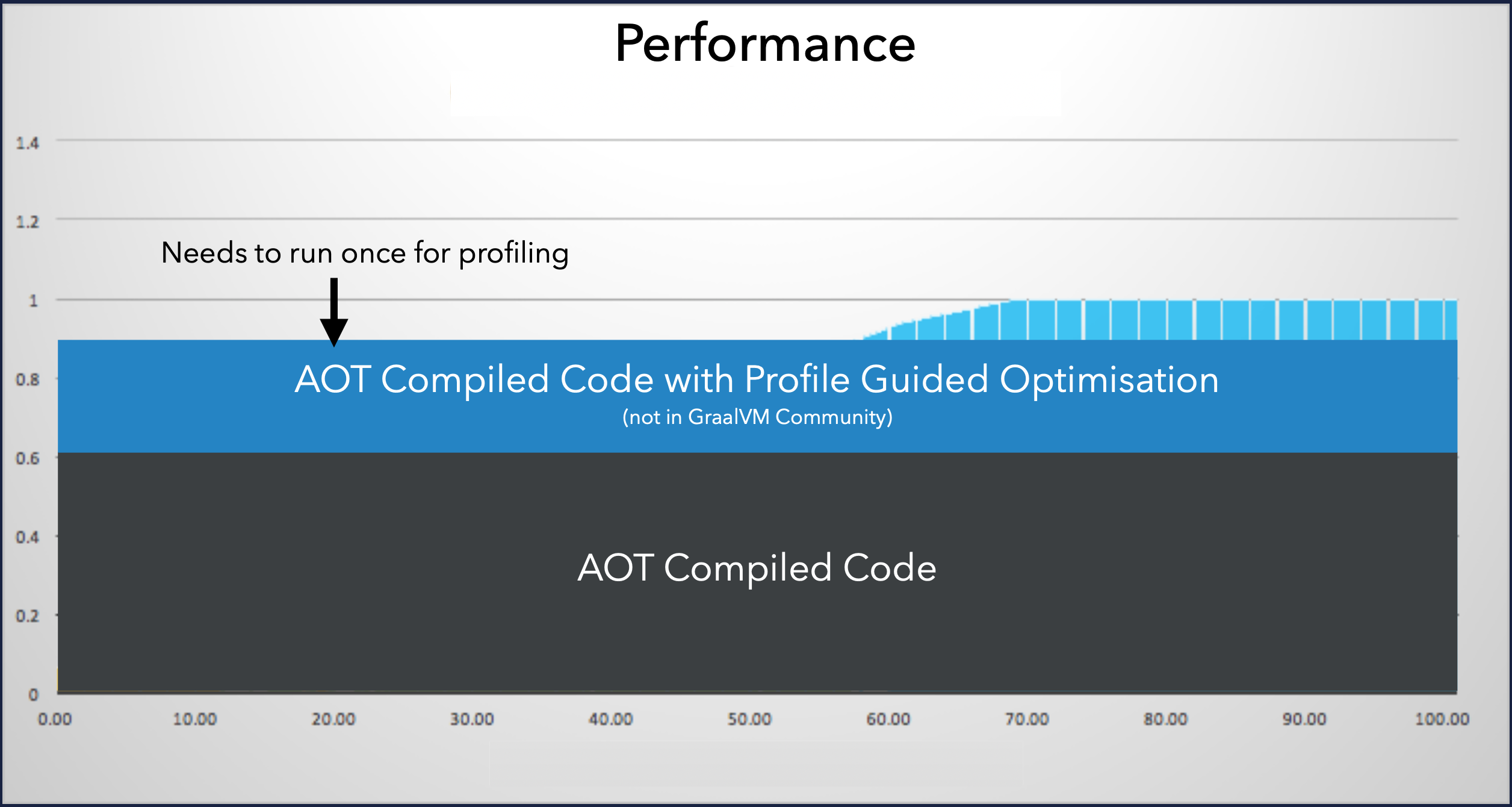
- 兼容性问题 AOT 对 Java 的动态特性(如反射、动态代理、运行时字节码生成)支持有限,通常需要额外的配置或代码调整,并非所有 Java 库都能直接兼容。
# JIT 的优势:运行时动态优化的威力
与 AOT 的静态编译不同,JIT 编译是在程序运行期间进行的。这赋予了 JIT 编译器独特的优势,使其能够进行比 AOT 更深层次、更精准的优化。
- 基于真实运行情况的优化: JIT 编译器可以观察到代码实际的运行路径、热点方法、分支跳转频率、数据类型分布等信息。基于这些动态收集的信息,JIT 可以做出更明智的优化决策。
- 激进的优化策略: JIT 可以采用更激进的优化手段,例如:
- 方法内联 (Method Inlining): 将调用频繁的小方法直接嵌入到调用处,消除方法调用的开销。JIT 可以根据实际调用情况决定是否内联以及内联的深度。
- 逃逸分析 (Escape Analysis): 分析对象的作用域,如果一个对象只在方法内部使用,不会“逃逸”出去,JIT 可以将其分配在栈上而不是堆上,减轻 GC 压力,甚至进行锁消除。
- 投机性优化 (Speculative Optimizations): JIT 可以根据观察到的高概率事件进行优化(例如,假设某个类型检查总是成功),并准备好在假设失败时回退到较慢的代码路径(Deoptimization)。AOT 通常无法承担这种风险。
- 针对特定环境的优化: JIT 编译器知道程序当前运行的 CPU 架构(例如 Haswell, Skylake, Ice Lake 等),可以生成针对该特定 CPU 指令集优化的机器码,最大化硬件性能。AOT 为了通用性,通常只能编译为“最小公分母”的指令集。
- 支持 Java 动态特性: JIT 天然与 Java 的动态特性(如反射、运行时字节码生成)协同工作,这些特性对于 AOT 来说往往是难点。
正是由于这些基于运行时信息的动态优化能力,经过充分预热的 JIT 代码通常能够达到比 AOT 代码更高的峰值性能。
# JIT 的主要缺点
尽管 JIT 在峰值性能上有优势,但其缺点也显而易见,这正是 AOT 试图解决的问题。
- 启动时间长 (Requires more time to start up): JIT 需要经历 JVM 启动、类加载、解释执行、热点分析、代码编译等多个慢速操作后,才能达到较快的执行速度。
- 运行时编译开销 (CPU overhead to compile code at runtime): JIT 编译本身需要消耗 CPU 资源。
- 内存占用大 (Larger memory footprint): JVM、JIT 编译器、性能分析数据等都需要占用额外的内存。
# AOT vs. JIT 对比总结
| 特性 | AOT (Ahead-of-Time) | JIT (Just-In-Time) |
|---|---|---|
| 编译时机 | 运行前 (静态) | 运行时 (动态) |
| 启动速度 | 快 (Time to first response 短) | 慢 (需要 JVM 初始化、类加载、解释执行) |
| 预热时间 | 短 (几乎无预热) | 长 (需要识别热点、分层编译优化) |
| 峰值性能 | 通常较低 (缺乏运行时信息和动态优化) | 通常较高 (可进行激进优化、针对性优化) |
| 内存占用 | 小 | 大 (包含 JVM、JIT 编译器、分析数据等) |
| 动态特性支持 | 有限 (需配置或改造) | 良好 (Java 核心优势之一) |
| 运行时开销 | 低 (无编译开销) | 有 (编译 CPU 开销) |
| 兼容性 | 挑战较大 | 好 |
| 优化依据 | 静态分析 (+ 有限的 PGO) | 运行时真实行为 |
# CRaC 的切入点
理解了 AOT 和 JIT 各自的优劣后,CRaC 的价值就更加清晰了。
CRaC 试图结合两者的优点,规避其缺点:它保留了 JIT 带来的峰值性能优势(因为 Checkpoint 是在 JIT 充分预热后创建的),同时通过状态恢复的方式,避免了 JIT 漫长的启动和预热过程,实现了类似 AOT 的快速启动(特别是达到峰值性能的速度)。与 AOT 相比,CRaC 对 Java 动态特性的兼容性更好。
因此,CRaC、AOT 和传统的 JIT 代表了 Java 性能优化的不同策略,适用于不同的场景和需求。
# 三、实现原理:深入 CRaC 的心脏
CRaC 技术并非空中楼阁,它的实现依赖于一个强大的 Linux 工具:CRIU。虽然 CRIU 是一个运行在用户空间的程序,但它的核心能力建立在 Linux 内核提供的丰富特性和接口之上。理解 CRIU 的工作原理对于深入掌握 CRaC 至关重要。
# 基石:CRIU
CRIU (Checkpoint/Restore In Userspace) 是一个 Linux 用户空间的工具,它允许你“冻结”(Checkpoint)一个正在运行的应用程序(或一组应用程序),将其状态保存到磁盘文件中,然后在未来的某个时刻从这些文件中“解冻”(Restore)它。被恢复的应用程序将从被冻结的那个精确时刻继续运行,仿佛什么都没有发生过一样。CRIU 的核心能力是保存和恢复进程的各种资源状态。
# Checkpoint 过程详解
 Checkpoint 阶段会执行以下步骤。
Checkpoint 阶段会执行以下步骤。
- 收集进程树并冻结
CRIU 首先需要确定要 Checkpoint 的目标进程及其所有子进程和线程,构成一个完整的进程树。
/proc 是一个虚拟文件系统,它并不存在于磁盘上,而是由 Linux 内核动态生成,用来提供有关系统状态和正在运行的进程的信息。对于每个正在运行的进程,/proc 下都有一个以该进程的 PID(Process ID)命名的目录。
在一个进程内部,可能有一个或多个线程。在 Linux 内核看来,线程本质上也是一种“任务”(Task),它们共享同一个地址空间和其他资源,但有自己独立的执行流和调度标识符(TID, Thread ID)。/proc/$pid/task/ 这个目录就包含了该进程(PID 为 $pid)下的所有线程(任务)的信息。该目录下会为每个线程创建一个子目录,目录名就是该线程的 TID。
通过读取 /proc/$pid/task/ 目录的内容,CRIU 可以识别出属于进程 $pid 的所有线程(包括主线程和其他子线程),获取它们的 TID 列表。
/proc/$pid/task/$tid/children 文件位于特定线程的目录下,记录了由 这个特定线程(PID 为 $pid,TID 为 $tid)直接创建 的所有子进程的 PID 列表。子进程是由 fork() 或 clone() 系统调用创建的。这个 children 文件告诉我们,从这个线程出发,诞生了哪些新的进程。
CRIU 从 --tree 选项指定的那个初始 PID 开始,首先通过 /proc/$pid/task/ 找到一个进程的所有线程,然后通过 /proc/$pid/task/$tid/children 找到每个线程创建的子进程,再对这些子进程重复同样的操作,一层层深入下去,最终像剥洋葱一样把整个进程家族(包括所有进程和线程)都识别出来。
在遍历过程中,CRIU 使用 ptrace 系统调用,命令为 PTRACE_SEIZE,来附加(attach)到目标进程树中的每个任务(进程/线程)上,并将它们暂停下来。
传统的 PTRACE_ATTACH 依赖信号机制,PTRACE_ATTACH 会向目标进程发送 SIGSTOP,SIGSTOP 信号需要被目标进程的信号处理程序处理,然后进程才停止。
PTRACE_SEIZE 则不同,它不依赖用户空间的信号传递来让目标进程停止,是内核层面的一个直接操作。当调用 ptrace(PTRACE_SEIZE, tid, ...) 时,内核会标记目标任务(线程 tid)进入 ptrace-stop 状态,这个任务会在下一次内核有机会介入任务执行流的时候暂停。
- 收集任务资源并转储
进程树被冻结后,CRIU 开始收集每个任务的详细信息,并将这些信息写入镜像文件(dump files)。这些信息主要来源于 /proc 文件系统。
- 内存映射 (Memory maps)
CRIU 通过解析
/proc/$pid/maps和/proc/$pid/smaps获取虚拟内存区域(VMA)的布局信息。
/proc/$pid/maps 列出了当前进程 ($pid) 所有内存映射区域(Virtual Memory Areas - VMA) 的详细信息,每一行代表一个连续的虚拟内存区域,通常包含以下字段,用空格分隔:
|
|
如果是文件映射,设备号表示文件所在的设备,inode 表示文件的 inode 编号,路径名会显示被映射文件的路径。
对于匿名映射,即没有关联具体文件,如 malloc 分配的内存、进程的堆、栈等,inode 值为 0,路径名通常为空,或者显示一些特殊标记,如 [heap] 表示进程的堆内存区域,[stack]表示进程的主线程栈区域。
例如查看应用服务器进程的 maps 文件内容:
|
|
/proc/$pid/maps 是 CRIU 理解进程内存布局的核心依据,而 /proc/$pid/smaps 是 /proc/$pid/maps 的一个扩展版本。
/proc/$pid/smaps为每一个内存映射区域(VMA)提供了更详细的内存占用统计信息(物理内存占用、共享/私有、干净/脏、匿名、交换、锁定等),以及重要的内核内部标志 (VmFlags)。smaps 由多个块 (block) 组成,每个块对应 /proc/$pid/maps 文件中的一行(即一个 VMA)。
还是以应用服务器进程为例:
|
|
- 内存映射文件(mapped files)
/proc/$pid/map_files/ 是一个目录,这个目录包含了指向实际被映射文件的符号链接 (symbolic links)。目录中的每个符号链接的名称对应于 /proc/$pid/maps 文件中列出的一个内存区域的地址范围 (格式为 起始地址 - 结束地址)。
CRIU 通过 /proc/$pid/map_files/ 获取文件映射区域底层文件对象的直接链接,主要用于可靠地访问和读取这些文件映射区域的内容。
|
|
- 文件描述符 (File descriptors)
CRIU 通过读取 /proc/$pid/fd 和 /proc/$pid/fdinfo 获取进程打开的文件、管道、套接字等信息。CRIU 能够处理各种类型的文件描述符,包括常规文件、管道、Unix 套接字、TCP 套接字(甚至包括处于 ESTABLISHED 状态的连接)。
/proc/$pid/fd是一个目录,它包含符号链接,每个符号链接的名称对应一个已打开的文件描述符编号。例如:
|
|
/proc/$pid/fdinfo也是一个目录,它包含普通文件(不是符号链接),每个文件的名称对应一个已打开的文件描述符编号。每个文件(例如/proc/$pid/fdinfo/1)包含关于相应文件描述符的元数据和状态信息。例如:
|
|
/proc/$pid/fd告诉 CRIU 通过哪些描述符编号打开了哪些资源,/proc/$pid/fdinfo告诉 CRIU 每个已打开描述符的状态和元数据(比如位置和标志)。CRIU 使用来自这两个位置的信息来完整保存进程已打开文件及其状态的情况,以便之后能够准确地恢复它们。
- 核心运行参数 (Core parameters)
为了保存一个任务(进程/线程)的核心运行状态以便后续恢复,CRIU 主要结合使用了两种方法。
使用 ptrace 系统调用的特定命令(例如PTRACE_GETREGS 或 PTRACE_GETFPREGS )来直接读取任务暂停时的CPU 寄存器 (registers) 内容,包括通用寄存器、指令指针、标志寄存器、浮点寄存器等),以及其他密切相关的底层执行状态信息。
通过读取和解析 /proc/$pid/stat 文件,获取关于任务的各种状态参数和统计数据。/proc/$pid/stat 以单行文本的形式提供了关于进程的大量状态信息 (status information),其中的信息由空格分隔,每个字段代表一个特定的进程属性或统计值。下面列出一些最核心和常用的字段:
- 可执行文件名 (comm)
- 进程状态 (state)
- 父进程 ID (ppid)
- 进程组 ID (pgrp)
- 会话 ID (session)
- 调度优先级和 nice 值 (priority, nice)
- 虚拟内存大小 (vsize)
- 常驻集大小 (rss)
- 进程启动时间 (starttime)
- 等待子进程的 CPU 时间 (cutime, cstime)
- 注入寄生代码(Parasite Code)并转储内存
为了获取某些无法从外部直接探测的信息(例如进程凭证、精确的内存布局和内容),CRIU 必须在目标进程的地址空间内部执行特定的代码。这正是通过 寄生代码 (Parasite Code) 技术实现的。
寄生代码是一段精心构造的小型二进制程序,它以位置无关可执行文件 (PIE, Position-Independent Executable) 格式编译。这一特性至关重要,因为它允许 CRIU 将这段代码加载到目标进程地址空间中的任何可用位置,而无需担心因硬编码地址引发的冲突。该代码通常包含两部分:一小段依赖于具体处理器架构(如 x86, ARM)的汇编引导程序 (bootstrap),以及一段用 C 语言编写、负责处理命令的通用核心逻辑 (daemon)。

要在目标进程中运行,寄生代码需要自己的内存空间来存放其代码、运行栈以及用于和 CRIU 进行通信的参数区域。由于 CRIU 不能直接操作目标进程的内存分配,它巧妙地利用了 ptrace 机制:
- 准备内存空间
- CRIU 首先使用
ptrace控制目标进程,并保存其当前的寄存器状态(尤其是指令指针 CS:IP 和栈指针)。 - 接着,CRIU 修改目标进程的寄存器,填入执行
mmap系统调用所需的编号和参数。 - 通过
ptrace(PTRACE_SYSCALL,...),强制目标进程执行这个 mmap 调用。这会在目标进程的地址空间中分配一块共享内存区域。
- CRIU 首先使用
- 注入并执行寄生代码
- CRIU 使用
ptrace(PTRACE_POKEDATA, ...),将预先编译好的完整寄生代码二进制数据写入到刚刚分配的共享内存区域中。 - CRIU 再次使用
ptrace修改目标进程的寄存器,将指令指针 (IP/PC) 指向共享内存中寄生代码的入口点。 - CRIU 命令目标进程恢复执行
ptrace(PTRACE_CONT, ...)。此时,目标进程便开始执行被注入的寄生代码。
- CRIU 使用
寄生代码运行在目标进程的上下文中,因此拥有访问该进程所有资源的权限。它可以执行 CRIU 指派的各种任务,例如读取和转储私有内存页、收集文件描述符的详细状态等。
- 清理 (Cleanup)
当所有需要通过寄生代码完成的任务结束后,必须将其彻底移除,并将目标进程恢复到之前的状态,仿佛从未被打扰过:
- 寄生代码退出
- CRIU 通过共享内存或专用通信通道向寄生代码发送一个结束命令 (
PARASITE_CMD_FINI)。 - 寄生代码收到命令后,执行必要的清理操作,然后调用
rt_sigreturn()系统调用。此系统调用会利用 CRIU 事先准备好的信息,恢复目标进程在寄生代码注入前一刻的寄存器状态。
- CRIU 通过共享内存或专用通信通道向寄生代码发送一个结束命令 (
- CRIU 清理环境
- CRIU 通过
ptrace监视系统调用,并拦截rt_sigreturn()的退出。 - 在目标进程寄存器已恢复、但寄生代码的内存区域还在的短暂时刻,CRIU 再次利用
ptrace强制目标进程执行 munmap 系统调用,将之前为寄生代码分配的共享内存区域解除映射,彻底抹除其痕迹。
- CRIU 通过
- 恢复正常运行
- 最后,CRIU 调用
ptrace(PTRACE_DETACH, ...)从目标进程分离。 - 目标进程从其原始被中断的指令处(由恢复的寄存器状态决定)继续执行,整个进程树恢复运行,Checkpoint 操作完成。
- 最后,CRIU 调用
# Restore 过程详解

Restore (恢复) 过程可以看作是 Checkpoint (检查点) 的逆向操作。在这个过程中,执行恢复命令的 CRIU 进程会经历一系列精心设计的步骤,最终“变形”成为检查点时刻被冻结的目标进程(或进程树),并从那一刻继续运行。整个过程大致分为以下四个主要阶段:
- 解析共享资源
CRIU 首先读取检查点生成的镜像文件,分析进程间的依赖关系。它会找出哪些资源实例(例如:同一个会话 ID、同一个打开的文件描述符指向的内核文件对象、同一块共享内存区域等)是被多个进程共同使用的。
识别出这些共享资源后,CRIU 会标记它们,并确定恢复策略。某些资源会通过继承(如会话 ID,在 fork() 时由子进程自然获得),其他的则需要更复杂的机制,比如利用 Unix domain socket 和 SCM_RIGHTS 消息 在进程间传递文件描述符,或者使用 memfd 等技术来重建共享内存区域。这一步是为了确保在后续阶段,这些共享资源能被正确地创建一次,并被所有相关的进程共享,而不是各自创建独立的实例。
- 创建进程树
CRIU 严格按照镜像文件中记录的父子关系,通过多次调用 fork() 系统调用来重新创建原始的进程树。每个 fork() 都会产生一个新的进程,其父进程是之前已恢复的对应父进程。
注意,在这个阶段,只创建进程的主线程。目标进程的所有其他线程的恢复会被推迟到最后一个阶段,主要是为了简化后续内存布局调整时的同步问题。
- 恢复基本任务资源
在这个阶段,CRIU 为进程树中的每个进程恢复除了少数几类特殊资源之外的大部分状态。此时恢复的资源包括:
- 文件描述符: 打开检查点时记录的文件(使用保存的路径、访问模式、标志位),并根据需要设置到确切的文件偏移量。对于管道、套接字等也会进行创建。
- 命名空间 (Namespaces): 如果进程使用了非默认的命名空间(如 PID、Mount、Network、IPC、User、UTS),CRIU 会创建或加入相应的命名空间,隔离进程环境。
- 私有内存映射: 映射进程的私有内存区域(如代码段、数据段、堆、匿名映射等),并从镜像文件中读取检查点时保存的数据,填充到这些内存区域中。
- 套接字 (Sockets): 创建套接字,并恢复其状态(如 TCP 连接的状态,如果检查点时保存了相关信息并配置了 TCP 修复)。
- 工作目录与根目录: 调用 chdir() 和 chroot() 恢复进程检查点时刻的当前工作目录和根目录。
- 其他: 还可能包括恢复信号处理器、进程的 umask 等。
有四类关键资源在此阶段不会被完全恢复,它们的恢复被特意推迟到了最后阶段:
- 内存映射的确切虚拟地址(此阶段可能映射在临时地址)。
- 定时器 (Timers)。
- 凭证 (Credentials) (如 UID, GID, Capabilities)。
- 线程 (Threads) (除了主线程)。
这几类资源之所以延迟恢复,主要是因为它们要么依赖于最终的内存布局,要么涉及特权操作,要么在最终执行前恢复可能导致状态不一致或复杂化处理。
- 切换到 Restorer Context,恢复剩余资源并继续执行
这是最关键的一步。因为执行恢复操作的 CRIU 代码本身就位于需要被替换掉的内存区域中。直接执行 munmap() 卸载旧内存或 mmap() 映射新内存到当前地址,都会导致 CRIU 自身崩溃。
为了解决这个问题,CRIU 引入了一个 Restorer Context (恢复器上下文),这是一小段自包含的、位置无关的 (PIE) 代码,不依赖外部库,并且被加载到一个临时的、既不属于 CRIU 主体也不属于目标进程最终内存布局的“安全地带 (safe zone)”。
CRIU 准备好恢复所需的数据(如最终内存映射信息、线程状态、凭证等),找到合适的内存“空洞”加载恢复器代码和数据,然后通过一次跳转,将 CPU 的执行控制权转移给这段恢复器代码。
在 Restorer Context 中,完成最后几项资源的恢复:
- 内存映射 (Memory): 使用
mremap()将之前映射在临时地址的私有匿名内存移动到最终的目标虚拟地址。使用mmap()在正确的地址创建文件映射和共享内存映射(可能通过之前准备好的memfd文件描述符来实现共享)。此时,完整的、精确的进程内存布局被建立起来。 - 定时器 (Timers): 恢复并启动所有的定时器。因为此时环境已稳定,可以避免定时器过早触发或计时偏差。
- 凭证 (Credentials): 设置进程最终的用户 ID、组 ID、能力集等。这通常在需要特权的操作(如
fork()指定 PID)完成后,但在彻底放弃特权之前进行。 - 线程 (Threads): 在最终的内存布局中,根据保存的状态创建并恢复目标进程的所有其他线程。
最后,Restorer Context 完成所有设置后,它会精确地恢复目标进程主线程的寄存器状态(包括最重要的指令指针 IP/PC,指向检查点时刻被中断的那条指令),然后将 CPU 的控制权彻底交还给目标进程。至此,目标进程就像从未被打断过一样,从检查点时刻的状态无缝地继续执行。
# CRIU 小结
CRIU 通过 ptrace 和精心设计的寄生代码机制,以及对 /proc 文件系统的深度利用,实现了在用户空间对运行中进程进行 Checkpoint 和 Restore 的强大能力,为 CRaC 技术的实现奠定了坚实的基础。
# CRaC 的设计理念
理解了 CRIU 的强大能力后,一个自然的问题是:既然 CRIU 能够处理打开的文件描述符和网络连接,甚至可以透明地恢复它们,为什么 CRaC 却要求开发者通过 API(jdk.crac.Resource)来手动管理这些外部资源,通常需要在 beforeCheckpoint 中关闭它们,在 afterRestore 中重新建立它们呢?
对于这个问题,我查阅了 CRaC 所有相关的文档,阅读了 CRaC 原型实现的源码,都没有获得满意的答案。于是在 CRaC 的开发者邮件列表中询问,最终从核心 Committer 的回复中得到解答。

根据 CRaC 开发者的阐述,这并非技术上的限制,而是一个深思熟虑的架构选择 (architectural choice)。其核心设计理念可以概括为 协调与适应。
CRIU 的主要动机之一是实现运行中容器的透明迁移。在容器迁移场景下,环境(文件系统、网络)通常是被精心管理的。容器运行时(如 Docker、Kubernetes CRI)可以配合 CRIU 工作,确保恢复后,外部环境(比如网络连接的对端、挂载的文件系统)仍然有效或被正确地重新建立,从而对容器内的进程做到“透明”。比如,网络连接恢复时,容器运行时会处理好 IP 地址、路由等问题。
如果你追求的是 CRIU 那种“透明恢复”,理论上可以直接在 Java 进程上使用 CRIU。但这有风险,可能会破坏应用程序的内部逻辑。因为 Java 应用可能依赖外部资源的状态,如果环境变化而应用没有感知和调整,就会出问题(比如数据库连接指向了旧的、不存在的 IP,或者文件句柄指向了一个在恢复环境中已变化或不存在的文件)。
CRaC 的目标不是追求完全透明的恢复。它想要的是:保留 JVM 和应用程序内部计算的有价值的状态(比如 JIT 编译结果、缓存数据、业务逻辑状态),但要让应用程序有机会主动适应恢复时可能已经变化的新环境。
CRaC(Coordinated Restore at Checkpoint) 的名字强调了“协调”(Coordinated)。它要求应用程序通过实现 Resource 接口来参与 Checkpoint 和 Restore 过程。CRaC 希望开发者对每一个外部资源(文件、网络连接、数据库连接等)在恢复时如何处理,做出有意识的决定:这个资源在 Checkpoint 前应该如何处理(通常是关闭)?在 Restore 后应该如何处理(通常是重新建立或验证)?
这种强制性的协调机制被 CRaC 视为一个特性 (feature),而不是一个缺陷。这确保了应用程序能够优雅地适应 (gracefully adapt) 恢复后的新环境,而不是盲目地假设外部世界一成不变。通过显式地关闭和重新建立连接、验证文件句柄等操作,可以大大提高应用程序在 Restore 后的健壮性和正确性。
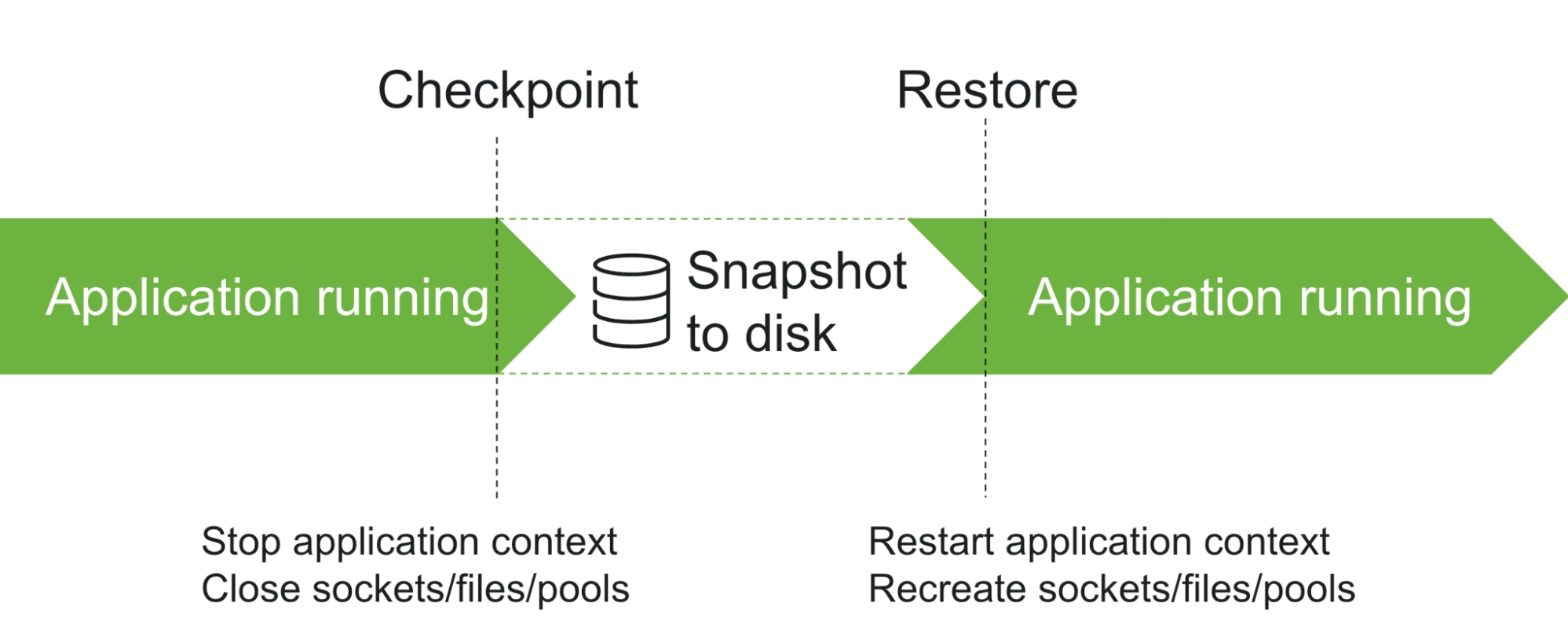
简而言之,CRaC 的设计哲学是,牺牲一定的透明度,换取应用在恢复后对环境变化的健壮适应能力。它要求开发者更加明确地思考和管理应用的外部依赖。虽然这在初期可能带来一些额外的工作(比如处理日志文件句柄),但其目的是为了确保应用在 CRaC 恢复后能够稳定、正确地运行在一个可能已经发生变化的新环境中。
# OpenJDK CRaC 实现概览
了解了 CRaC 的设计理念和底层依赖 CRIU 后,我们来看看 CRaC 功能在 OpenJDK 内部的大致实现流程。这个过程涉及 Java API 层、JVM 内部实现、外部引擎(默认是包装了 CRIU 的 criuengine)以及操作系统层面的交互。
# Checkpoint 流程概览
Checkpoint 过程的目标是安全地停止 JVM,通知所有已注册的资源进行准备,然后调用外部引擎来创建进程镜像。
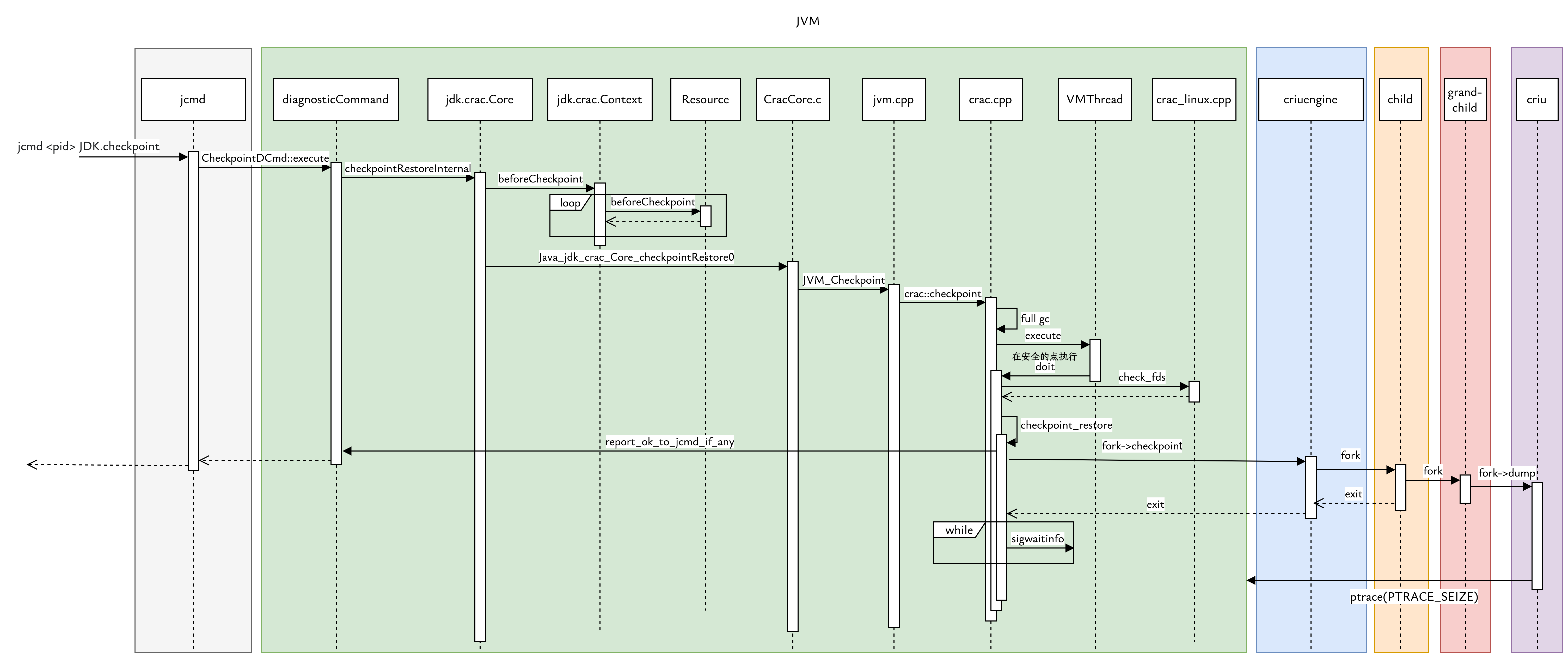
- 触发 Checkpoint
用户执行 jcmd <pid> JDK.checkpoint,CheckpointDCmd::execute 被调用,它解析 jdk.crac.Core 类,并调用其静态方法 checkpointRestoreInternal(long jcmdStream)。jcmdStream 是用于输出 jcmd 结果的流。
- Java 层准备
遍历所有注册到全局上下文 Context的 Resource 实现,并调用它们的 beforeCheckpoint 方法。Resource 在此方法中执行必要的清理或准备工作(例如,关闭不需要的网络连接、刷新缓冲区等)。
- 进入 JVM/Native 层
调用 native 方法 checkpointRestore0(int[] fdArr, Object[] objArr, boolean dryRun, long jcmdStream)。
定义在 CracCore.c 中的 JNI 实现 Java_jdk_crac_Core_checkpointRestore0 调用 JVM_Checkpoint。
JVM_Checkpoint 是一个 JVM 标准入口点,它调用 crac::checkpoint,正式进入 CRaC 的 checkpoint 阶段。
- JVM 内部 Checkpoint 准备
crac::checkpoint 是 CRaC 的主入口,首先执行一次强制 Full GC (GCCause::_full_gc_alot) ,清理未使用的堆区域,以减小镜像体积。
然后通过 VMThread::execute() 进入 JVM 的 Safepoint,这是所有的 Java 线程都已暂停,准备好执行接下来的 checkpoint 操作。
- checkpoint 操作执行
遍历 /proc/self/fd 下的所有文件描述符,如果有应用程序打开但未声明的资源,会导致 Checkpoint 失败,操作会提前返回,最终导致 Java 层抛出 CheckpointException。
如果一切顺利,调用 report_ok_to_jcmd_if_any()。这会向 jcmd 客户端发送一个初步的成功响应,然后才调用外部引擎。这样做是因为外部引擎(如 CRIU)通常会杀死原始 JVM 进程,所以响应必须在此之前发送。
接着在 call_crengine fork 新的进程,加载外部引擎 criuengine,执行 criuengine的 checkpoint方法。
在checkpoint方法中使用 double fork 技巧,让孙子进程执行 CRIU,这样 CRIU 进程就不再是 JVM 的子进程。
孙子进程执行的具体命令是 criu dump -t <jvm_pid> -D <checkpoint_dir> --shell-job [options...],冻结 JVM 进程,将其状态保存到 <checkpoint_dir> 下的镜像文件中,然后 杀死 原始的 JVM 进程。
- JVM 暂停点
JVM 进程从 call_crengine 快速返回,继续执行至 sigwaitinfo() 阻塞。
|
|
当 JVM 完成检查点(checkpoint)后,会进入等待循环,后续恢复进程会通过RESTORE_SIGNAL信号唤醒 JVM。
# Checkpoint 的进程交互
在通过外部引擎 criuengine执行criu dump的过程中,使用了 Linux 常见的编程技巧double fork,主要原因是为了解耦:通过让中间进程快速退出,使得执行 criu dump 的孙子进程成为孤儿进程,被 init 进程收养,从而“逃离”了原始 JVM 的进程树。
最终执行 criu dump 的进程不属于原始 JVM 进程的进程树,这避免了 CRIU 在执行 Checkpoint 时尝试冻结其自身的问题,保证了 Checkpoint 操作的正确性。

上图总结了 Checkpoint 过程中涉及的多个进程的创建。
- JVM fork -> P1 (criuengine checkpoint): JVM 创建子进程 P1 运行
criuengine checkpoint,JVM 进程等待 P1。 - P1 fork -> P2: P1 创建子进程 P2,P1 等待 P2。
- P2 fork -> P3 & P2 exit: P2 创建孙子进程 P3,然后 P2 立即退出。
- P1 exit: P1 检测到 P2 退出,于是 P1 也退出。
- JVM 继续: JVM 检测到 P1 退出,
call_crengine返回,JVM 继续执行直到sigwaitinfo阻塞。 - P3 fork -> criu dump: P3 成为孤儿进程(被
init/systemd接管),创建criu进程,最终执行criu dump,冻结并杀死阻塞中的 JVM。
# Restore 流程概览
Restore 过程的目标是从 Checkpoint 镜像启动一个新的 JVM 实例,使其恢复到 Checkpoint 时刻的状态,然后继续执行。
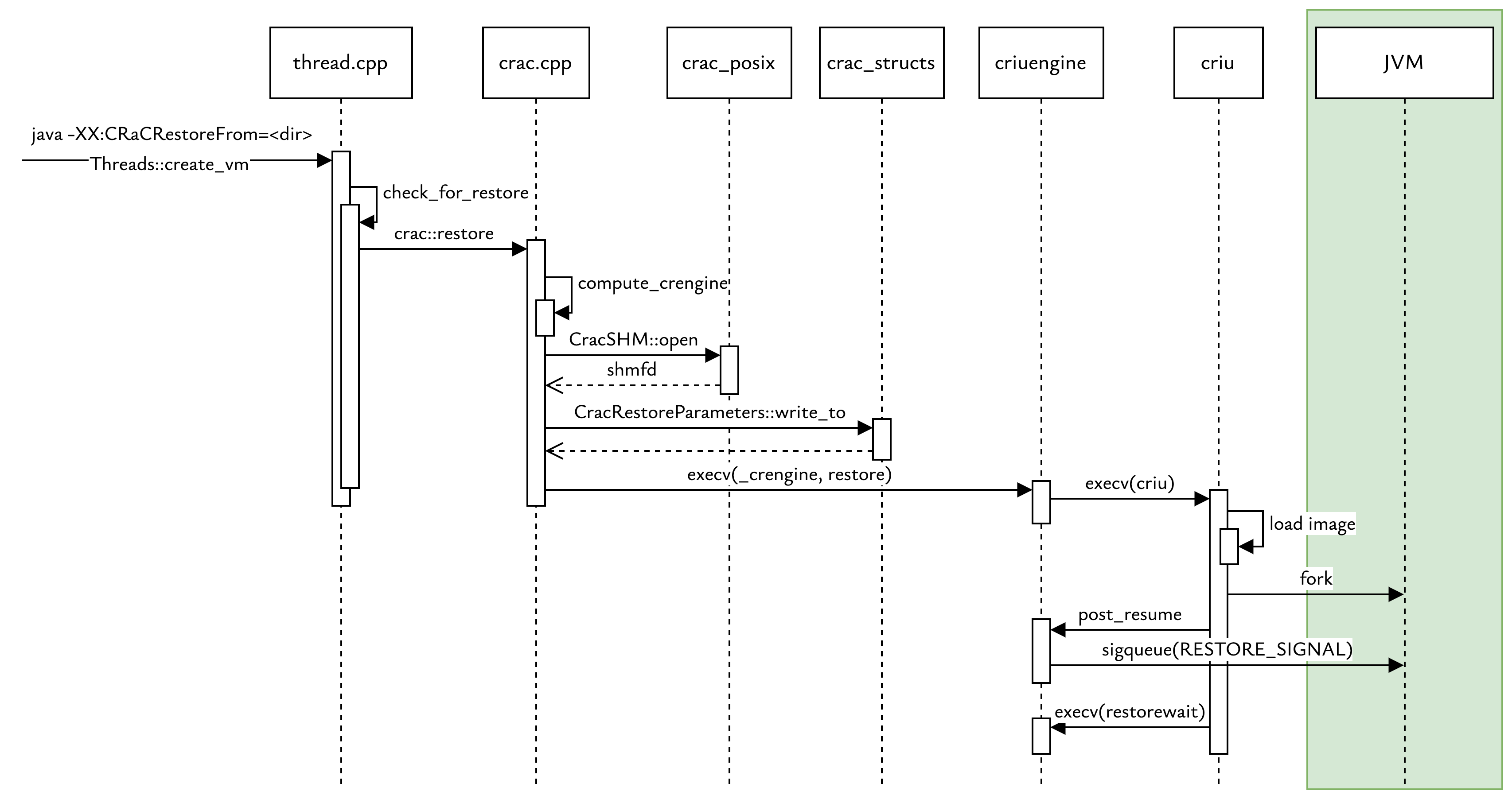
- 触发 Restore
用户启动 JVM,并指定 Restore 相关的参数 -XX:CRaCRestoreFrom=<checkpoint_dir>。
- JVM 初始化
在创建 JVM 的过程中,检测到 Restore 请求,调用 crac::restore()。
- 准备并切换引擎
进入 crac::restore() ,首先调用compute_crengine() ,确定外部引擎的路径和参数。
然后使用当前进程 ID (os::current_process_id()) 创建一个唯一的 共享内存 (SHM) 路径,打开 SHM 文件,并将 Restore 参数写入到 SHM(CracRestoreParameters::write_to)。SHM 用于在 crac::restore(初始 JVM)和恢复后的 JVM 之间传递新的启动参数、属性和时间戳。
最后调用 os::execv(_crengine, _crengine_args)。 execv 会用新的程序(外部引擎 criuengine)替换当前的 JVM 进程。初始启动的 JVM 到此结束。
- 外部引擎执行 Restore (criuengine restore)
外部引擎 criuengine 执行 restore 方法,构建 criu restore 命令参数。关键参数包括:
-D <checkpoint_dir>: 指定镜像目录。--action-script self: 指定criuengine自身作为 CRIU 的动作脚本。--exec-cmd -- self restorewait: 指定 CRIU 成功恢复进程后,应该执行criuengine restorewait命令。这个命令会等待恢复后的 JVM 进程结束。
执行 execv 运行 criu restore 命令,再次替换当前进程。
- CRIU 执行恢复
CRIU 读取镜像文件,在内存中重建 JVM 进程的状态(内存映射、线程状态、寄存器等)。
在进程状态基本恢复但尚未完全运行时,CRIU 会调用 --action-script 指定的脚本(即 criuengine),进入 post_resume 方法。
在post_resume 方法中,获取恢复后的 JVM PID 和之前存入的 SHM ID,然后使用 sigqueue 向恢复的 JVM 进程发送 RESTORE_SIGNAL 信号。
- 外部等待进程 (criuengine restorewait)
根据参数 --exec-cmd 指定的命令,再次执行 execv,将执行恢复的 CRIU 进程替换为 criuengine restorewait。
criuengine 使用 waitpid 等待刚刚恢复并继续运行的 JVM 进程,它会捕获发给它自己的信号,并尝试将这些信号转发给 JVM 进程。
当 JVM 进程最终退出时,waitpid 返回,criuengine 进程也以相同的退出码或基于信号的状态退出。
- 恢复的 JVM 继续执行
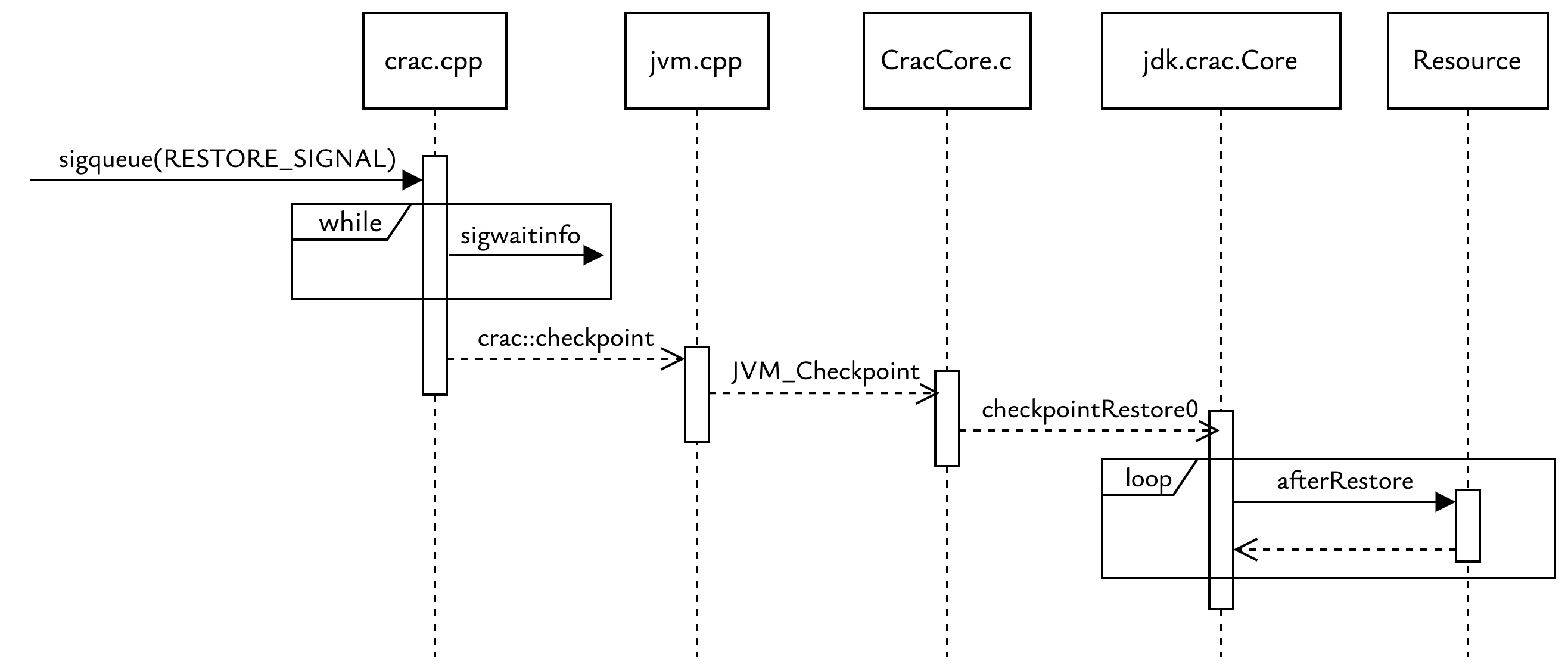
恢复的 JVM 进程收到 CRIU 进程发送的 RESTORE_SIGNAL 信号,从 sigwaitinfo() 醒来,执行流回到 checkpoint_restore 函数(在 crac.cpp 中),正好在 call_crengine() 之后等待信号的地方。
执行一些 JVM 恢复动作,包括根据 SHM ID 从共享内存中读取新的命令行参数,进行时间校准,唤醒可能在 Checkpoint 时处于 sleep 或 park 状态的线程。
- 返回 Java 层
JVM 将新参数返回给 jdk.crac.Core,Core 应用新属性,遍历所有注册的 Resource,调用其 afterRestore 方法,执行恢复后的初始化工作(例如,重新建立连接、重新加载配置等)。
- 完成
如果没有异常,从 Core.checkpointRestoreInternal 正常退出,Restore 成功,JVM 继续运行。
# Restore 的进程交互
Restore 过程巧妙地利用了 execv 系统调用来替换当前进程的映像,从而将控制权逐步交给下一个阶段所需的工具,最终恢复目标 JVM 进程。需要注意的是,在这个流程中,fork 并不像 Checkpoint 流程那样显式地用于创建等待子进程的父进程,而是由 CRIU 内部管理,但 execv 是贯穿始终的关键。
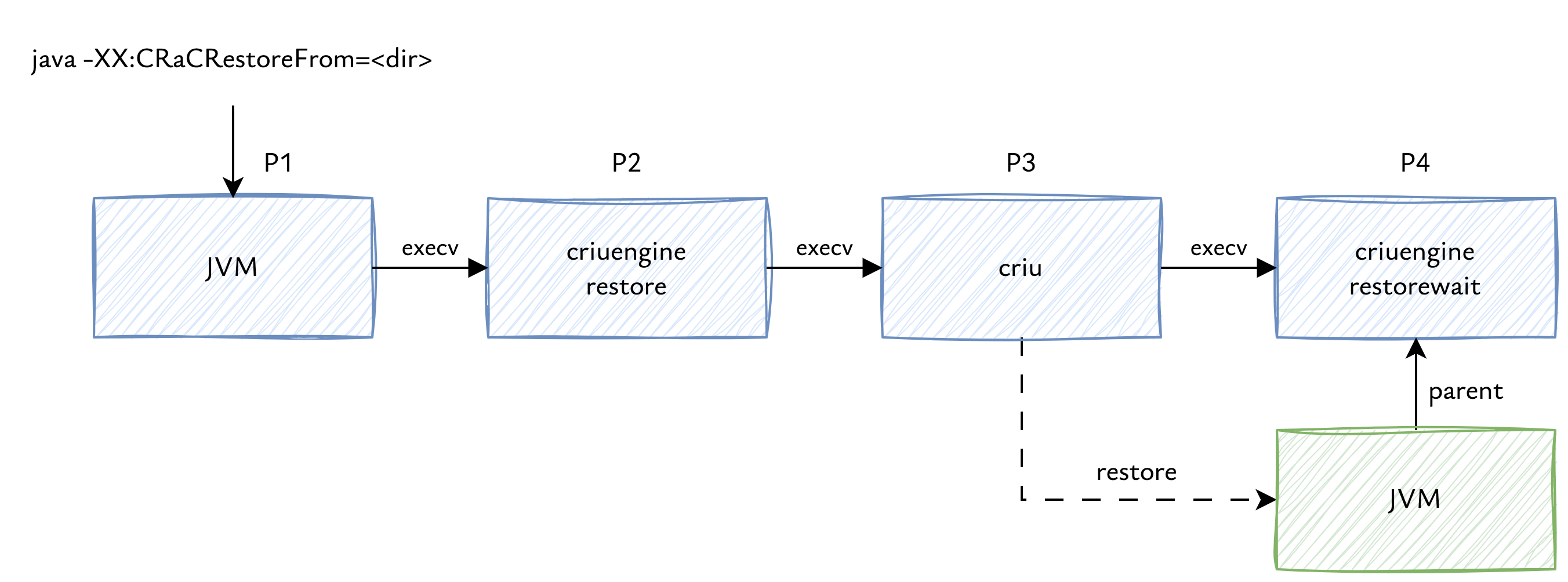
-
启动 Restore 命令 (用户 -> P1) 用户执行
java -XX:CRaCRestoreFrom=<checkpoint_dir>命令,启动了一个初始的 JVM 进程,我们称之为 P1。 -
P1 执行第一次
execv(P1 -> P2:criuengine restore) 在crac::restore()中,P1 准备必要的参数,调用os::execv(_crengine, _crengine_args),这里的_crengine是criuengine的路径,_crengine_args包含了 “restore” 和 Checkpoint 目录等参数。
结果 execv 用 criuengine restore 程序替换了 P1 进程。原来的 Java 进程 P1 不复存在。现在的进程我们称之为 P2,虽然 PID 可能与 P1 相同,但运行的程序已改变,P2 正在执行 criuengine restore 的代码。
-
P2 执行第二次
execv(P2 -> P3:criu restore) P2 运行criuengine restore代码,进行一些准备工作,构建 criu 命令行的参数,调用execv(criu, const_cast<char **>(args.data())),用criu restore程序替换了 P2 进程。criuengine restore进程 P2 不复存在。现在的进程(我们称之为 P3)正在执行criu restore。 -
P3 (CRIU) 恢复 JVM 进程,执行第三次
execv(P3 -> P4:criuengine restorewait) P3 (运行criu restore)读取 Checkpoint 镜像文件,恢复(fork)目标 JVM 进程。
在成功恢复 JVM 之后,CRIU 本身需要结束。由于指定了 --exec-cmd -- self restorewait,CRIU 会执行最后一次 execv,用 criuengine restorewait 程序替换了 P3 进程。criu restore 进程 P3 不复存在,现在的进程(我们称之为 P4)正在执行 criuengine restorewait。与此同时,JVM 已经独立运行起来,并完成了 Restore 的 Java 层逻辑。
- P4 (
criuengine restorewait) 等待 JVM P4 (运行criuengine restorewait代码)获取 JVM 的 PID,设置信号处理程序,尝试将接收到的信号转发给 JVM。最后调用waitpid(pid_P_JVM, &status, 0),等待 JVM 进程终止。当 JVM 退出时,P4 获取其退出状态,然后 P4 也以相同的状态退出。
简单来说,当 JVM 恢复时,通过 java -XX:CRaCRestoreFrom=... 启动的进程并不会启动 JVM,而是通过 criuengine 执行 CRIU,后者将恢复的进程作为其子进程启动。当 CRIU 完成进程重建后,它会执行 criuengine restorewait ,该程序的唯一任务是等待其唯一子进程(恢复的 JVM)退出并传递其状态。这意味着现在有两个进程,恢复的 JVM 进程是 criuengine 的子进程。
# 四、CRaC 使用指南
本章将详细介绍如何在你的 Java 应用程序中使用 CRaC 技术,包括理解其协调机制、使用 API、文件描述符策略以及通过一个 Jetty 示例进行实战演练。
# 为何需要 org.crac 包
CRaC 的核心 API(如 Resource 接口)最初存在于不同的包路径下(例如早期的 javax.crac 或 JDK 内部的 jdk.crac)。为了提供一个稳定且兼容的编程接口,社区引入了 org.crac 这个独立的库。
使用 org.crac 库的好处在于:
- 平滑采用: 开发者可以依赖这个库来编写 CRaC 相关的代码。
- 跨运行时兼容: 应用程序可以在不同的 Java 运行时上编译和运行,无论该运行时是否内置了 CRaC 支持(如标准的 OpenJDK、带有 jdk.crac 的 CRaC 构建版本,或者更早期的 javax.crac 实现)。
- 未来适应性: 即便未来 CRaC API 的包路径发生变化,应用程序代码也无需修改,只需更新 org.crac 库版本即可。
org.crac 库的核心功能是作为 CRaC API 的一个适配器。
- 编译时: 它提供了与
jdk.crac(以及历史上的javax.crac)完全镜像的 API 接口,供开发者编译时依赖。 - 运行时:
org.crac使用反射机制来检测当前运行的 JVM 是否包含实际的 CRaC 实现(检查是否存在jdk.crac.Core或javax.crac.Core)。- 如果检测到 CRaC 实现,所有对
org.cracAPI 的调用都会被转发给底层的实际实现。 - 如果未检测到 CRaC 实现(例如在标准 OpenJDK 上运行),请求会被转发到一个虚拟(dummy)实现。这个虚拟实现允许应用程序正常运行,
Resource也可以注册,但任何尝试创建Checkpoint的请求(如调用Core.checkpointRestore())都会失败并抛出异常。
通过这种方式,org.crac 库确保了应用程序即使在不支持 CRaC 的环境中也能运行,同时在支持 CRaC 的环境中能够无缝对接。
# 添加 org.crac API 依赖
可以通过 Maven 或 Gradle 将 org.crac 库添加到你的项目中:
- Maven
|
|
- Gradle
|
|
# CRaC 的协调机制
如前所述,CRaC 的核心设计理念是“协调与适应”。虽然底层的 CRIU 能够冻结和恢复进程的大部分状态,但对于外部资源(External Resources),如打开的文件、网络连接(Socket)、数据库连接等,简单的透明恢复可能会导致问题。原因在于:
- 环境变化:
Restore发生时,运行环境可能已经改变(例如,IP 地址、主机名、挂载的文件系统内容)。直接恢复旧的资源句柄可能指向无效或错误的目标。 - 状态失效: 某些外部资源的状态可能具有时效性(例如,数据库连接超时、文件被其他进程修改)。
- 资源冲突: 恢复的进程可能尝试使用已被新环境占用的资源(例如,端口号)。
因此,CRaC 不选择让 CRIU 默认透明地处理这些外部资源,而是要求应用程序必须参与到 Checkpoint 和 Restore 的过程中,主动管理这些资源。这就是“协调”的含义。应用程序需要明确告知 CRaC 如何安全地处理这些外部连接和状态,以确保在 Restore 后能够正确地适应新环境。
为了实现这种协调,org.crac 包提供了核心的 Resource 接口:
|
|
需要管理外部资源的类可以实现 Resource 接口:
- 在 Checkpoint 前调用
beforeCheckpoint(Context<? extends Resource> context),用于释放/关闭外部资源,确保状态一致。如果无法准备好,抛出异常阻止 Checkpoint。 - 在 Restore 后调用
afterRestore(Context<? extends Resource> context),用于重新建立/验证外部资源,恢复状态。如果恢复失败,抛出异常。
通过 org.crac.Core.getGlobalContext().register(this) ,将实现了 Resource 的对象注册给 CRaC 运行时。注册顺序决定了 beforeCheckpoint 的调用顺序,而 afterRestore 则以相反顺序调用。
# 文件描述符策略 (File Descriptor Policies)
虽然 CRaC 推荐通过实现 Resource 接口来主动管理外部资源,但也提供了一种基于配置的备选方案,称为文件描述符策略 (File Descriptor Policies)。这主要用于处理那些难以修改以添加 Resource 回调的代码,例如第三方库或 JDK 内部代码(注意:此策略仅适用于通过 JDK API 打开的文件描述符,不适用于 Native 代码打开的 FD)。
# 配置方式
通过设置系统属性 jdk.crac.resource-policies 指向一个策略文件来启用。该文件采用类似 YAML 的格式,包含一个或多个规则,规则之间用 --- 分隔。以 # 开头的行是注释。
|
|
CRaC 在 Checkpoint 时会检查所有打开的文件描述符。对于每个 FD,它会按顺序查找策略文件中的规则,第一个匹配的规则将被应用,后续规则会被忽略。
每个规则必须包含 type 和 action 两个属性(值不区分大小写)。
可用类型 (type):
- file: 本地文件系统上的文件或目录。
- pipe: 匿名管道(命名管道使用 file 类型)。
- socket: 网络套接字(TCP, UDP 等)或 Unix 域套接字。
- filedescriptor: 无法通过以上类型识别的原始文件描述符(例如,由 Native 代码打开但通过 JDK API 暴露的)。
# 文件 (file) 规则
通过 path 属性匹配,支持 glob 模式。
**可用操作 (action)**支持:
- error: (默认) 打印错误并导致 Checkpoint 失败。
- ignore: 忽略此 FD,将其处理完全委托给底层的 Checkpoint/Restore 引擎(如 CRIU)。CRIU 通常会尝试验证并在 Restore 时重新打开文件。这是将处理责任交给 CRIU 的方式。
- close: 在 Checkpoint 前关闭文件。如果在 Restore 后尝试使用该 FD,会导致运行时异常。
- reopen: 在 Checkpoint 前关闭文件,并在 Restore 后尝试在相同位置重新打开它。
# 管道 (pipe) 规则
匿名管道无法通过名称识别,因此通常最多只有一个 pipe 规则。
可用操作 (action) 支持 error,ignore 和 close,含义和文件规则相同。
# 套接字 (socket) 规则
可以通过以下属性细化匹配:
- family:
ipv4/inet4,ipv6/inet6,ip/inet(任意 IP),unix。 - localAddress, remoteAddress: IP 地址或
*(任意地址)。 - localPort, remotePort: 端口号或
*(任意端口)。 - localPath, remotePath: Unix 套接字路径,支持 glob 模式。
可用操作 (action) 支持 error,ignore 和 close。reopen 也可以使用,它会在 Checkpoint 前关闭套接字,但目前重新打开的逻辑(特别是对于监听套接字)可能尚未完全实现。
# 原始文件描述符 (filedescriptor) 规则
用于匹配那些没有对应 Java 对象(如 FileOutputStream)的文件描述符。
可以通过数值 value: 123 ,或原生描述的正则表达式 regex: .*something.* (Java 正则语法) 来匹配。
可用操作 (action) 支持 error, ignore 和 close。
# 重要提示
文件描述符策略被认为是权宜之计,用于处理无法直接修改代码的情况。首选且更健壮的方式仍然是实现 Resource 接口,因为应用程序最了解如何正确、安全地处理其外部资源,尤其是在面对环境变化时。过度依赖 ignore 策略可能隐藏潜在的 Restore 后问题。
# CRaC 实战
下面我们通过一个简单的 Jetty Web 服务器示例,演示如何使用 org.crac API 来支持 CRaC。完整代码可在 example-jetty 仓库找到。
- 初始 Jetty 应用
假设我们有一个简单的 Jetty 应用:
|
|
- 添加 org.crac 依赖
在pom.xml(Maven) 或build.gradle(Gradle) 中添加org.crac依赖。
|
|
- 尝试 Checkpoint (预期失败)
编译并运行应用,启用 CRaC 并指定 Checkpoint 目录:
|
|
应用启动后,尝试访问 http://localhost:8080,应该能看到“Hello World”。
|
|
然后尝试触发 Checkpoint:
|
|
此时,应用控制台会打印类似以下的异常并退出,因为 Jetty 打开了监听端口(一个 Socket 文件描述符),而我们没有处理它:
|
|
- 实现 Resource 接口
我们需要让 ServerManager 实现 Resource 接口,在 Checkpoint 前停止 Jetty 服务器(关闭 Socket),在 Restore 后重新启动它。
|
|
将 Resource 注册到一个 Context 中,该 Context 将调用 Resource 的方法作为通知。有一个全局的 Context 可以作为默认选择。
|
|
- 再次尝试 Checkpoint (预期成功)
重新编译并运行应用
|
|
访问 http://localhost:8080 进行预热。然后再次触发 Checkpoint:
|
|
这次,你应该在应用控制台看到类似输出,表明 Jetty 被停止,然后 Checkpoint 被创建,最后原始 JVM 被杀死:
|
|
同时,在 cr 目录下会生成 Checkpoint 镜像文件。
|
|
- 从 Checkpoint 恢复
使用 -XX:CRaCRestoreFrom 参数启动一个新的 JVM 实例:
|
|
现在,你可以再次访问 http://localhost:8080,应用应该能够正常响应。
查看进程的父子关系:
|
|
和前面 CRaC 实现原理分析一致,恢复的 JVM 进程是 criuengine 的子进程。
# 注意事项
- 架构与环境限制 CRaC 的 Checkpoint 和 Restore 必须在相同的 CPU 架构(例如,都是 x64 或都是 ARM64)上进行。
此外,它目前主要依赖 Linux 操作系统和特定的支持 CRaC 的 JDK 构建版本(如 Azul Zulu CRaC builds, Apusic JDK with CRaC Support 等)。
-
系统时钟变化 应用程序需要注意,从 Checkpoint 到 Restore 之间可能存在显著的系统时钟跳跃。对于依赖时间的逻辑(如缓存过期、定时任务、同步机制),可能需要在 afterRestore 回调中进行校准或特殊处理,以避免因时间差导致的行为异常。虽然 OpenJDK CRaC 内部会尝试校准 System.nanoTime(),但应用层面的时间敏感逻辑仍需开发者关注。
-
幂等性
beforeCheckpoint和afterRestore的实现应该是幂等的,即多次调用也应该产生相同的结果或无副作用。 -
安全性 Checkpoint 镜像包含了 JVM 进程的完整内存状态,可能包含敏感数据(如密码、密钥、用户数据等)。必须像对待生产数据库备份一样,妥善保管 Checkpoint 文件,控制访问权限。
# 五、CRaC 的应用场景与生态
CRaC 技术以其显著缩短启动时间和实现即时峰值性能的优势,在多个领域展现出巨大的应用潜力,并且其生态系统正在逐步发展壮大。
# 理想应用场景
-
Serverless Functions (FaaS) 这是 CRaC 最典型的应用场景之一。Serverless 函数的冷启动延迟是影响用户体验和成本的关键因素。CRaC 可以将函数的启动时间从秒级降低到毫秒级,极大地改善冷启动性能,使得 Java 在 Serverless 领域更具竞争力。AWS Lambda SnapStart 就是基于类似 CRaC 的技术实现的。
-
微服务 在微服务架构中,服务实例需要频繁地启动、停止和水平扩展。CRaC 可以显著加快新服务实例的启动速度,提高自动伸缩(Auto-scaling)的响应能力和效率,尤其是在应对突发流量时。
-
批处理作业 对于需要快速启动、执行任务然后退出的批处理作业,CRaC 可以消除大部分启动开销,提高作业执行效率。
-
资源受限环境 在内存或 CPU 资源受限的环境中,CRaC 通过避免启动和预热阶段的高资源消耗,有助于更高效地利用资源。
# 框架与平台支持
随着 CRaC 技术的发展,越来越多的 Java 框架和平台开始提供对其的支持,以简化开发者的使用。
-
Spring Framework / Spring Boot 从 Spring Framework 6.1 和 Spring Boot 3.2 开始,提供了对 CRaC 的官方支持。开发者可以通过简单的配置(例如
-Dspring.context.checkpoint=onRefresh)实现应用启动时的自动 Checkpoint,或者手动触发 Checkpoint 以包含更完整的应用状态。Spring 会自动处理内部管理的资源(如数据库连接池、消息监听器等)的 CRaC 回调。 -
Micronaut Micronaut 框架提供了专门的 micronaut-crac 模块,可以方便地集成 CRaC 支持。它内置了对常见资源(如 Hikari 数据源、Redis 连接)的协调处理。Micronaut 的构建插件(如 Gradle 插件)甚至可以一键生成包含 CRaC 镜像的 Docker 镜像。
-
Quarkus Quarkus 从 2.10.0 版本开始内置了对 CRaC 的基本支持。利用 Quarkus 的构建时优化和 CRaC 的运行时恢复能力,可以进一步提升应用的启动性能。
-
AWS Lambda SnapStart 虽然底层实现细节未完全公开,但 AWS Lambda 的 SnapStart 功能在原理和效果上与 CRaC 非常相似,它允许用户为 Lambda 函数创建快照,并在调用时快速恢复,显著降低 Java Lambda 函数的冷启动延迟。这表明 CRaC 的理念已经在主流云平台上得到了应用和验证。
-
Azul Zulu Builds of OpenJDK Azul 作为 CRaC 技术的主要推动者之一,提供了包含 CRaC 功能的 OpenJDK 发行版(Zulu),支持 Linux/x64 和 Linux/ARM64 平台,并为 Windows 和 macOS 提供用于开发和测试的模拟版本。
# CRaC 部署方案
CRaC 的部署方案旨在收集 Java 应用程序初始化和预热所需的数据。
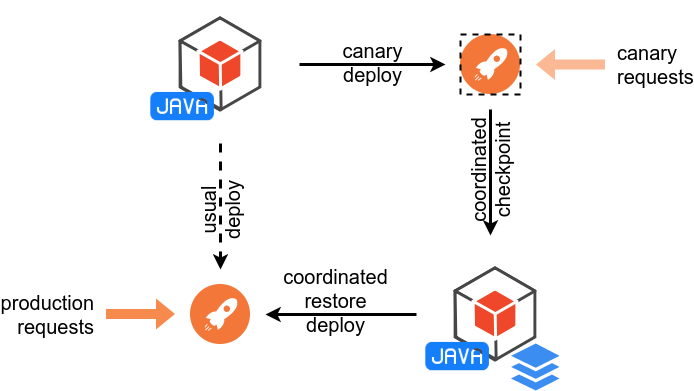
- 在金丝雀环境中部署并预热应用
- 将 Java 应用程序部署到金丝雀(canary)测试环境中。
- 应用程序处理金丝雀请求,这会触发类加载和 JIT 编译,从而完成预热。
- 创建 Checkpoint
- 对正在运行的应用程序进行 Checkpoint 操作。
- 这将创建 JVM 和应用程序的镜像(image),该镜像被视为新部署包的一部分。
- 在生产环境中部署和恢复
- 将带有镜像的 Java 应用程序部署到生产环境中。
- 通过
-XX:CRaCRestoreFrom=PATH选项从镜像恢复 Java 进程。 - 恢复后的 Java 进程将直接使用镜像中已加载的类和 JIT 代码,从而实现快速启动和即时达到最佳性能。
# 性能基准
由 Java 社区及主流框架开发者进行的广泛性能基准测试一致表明,CRaC (Coordinated Restore at Checkpoint) 技术能够为 Java 应用带来显著的性能提升,尤其在启动速度方面表现突出。

对于常见的 Web 应用程序,例如基于 Spring Boot、Micronaut 或 Quarkus 构建的应用,采用 CRaC 的恢复机制可以将原先需要数秒的启动过程,缩短至几十毫秒级别。这意味着应用能够更快地进入服务状态,提升用户体验和资源利用率。
为了具体展示 CRaC 的效果,我对 Glassfish 7 进行了 CRaC 的改造适配。在部署了标准 Spring PetClinic 应用的场景下:
- 常规启动耗时: 通过标准
./bin/asadmin start-domain命令启动,完成整个启动过程需要 8.813 秒 (8813 毫秒)。
|
|
- CRaC 恢复耗时: 从预先生成的 CRaC 快照 (checkpoint) 文件恢复,使用
java -XX:CRaCRestoreFrom=cr命令,启动过程仅需约 36.88 毫秒。
|
|
恢复时间计算:restore-finish - restore,恢复过程耗时为 519895630386924 - 519895593501838 = 36,885,086 纳秒,即 36.88 毫秒。
对比结果清晰显示,使用 CRaC 恢复,启动时间缩短了约 239 倍 (8813 ms / 36.88 ms),实现了数量级的性能飞跃。
除了惊人的启动速度提升,CRaC 更为核心的优势在于实现了“即时峰值性能”。与传统启动方式不同,恢复后的应用程序几乎可以瞬间达到其完全预热 (warmed-up) 后的最佳运行性能。这是因为它跳过了耗时的类加载、初始化以及 JIT (Just-In-Time) 编译器的早期编译和优化阶段。对于需要快速响应负载变化、频繁弹性伸缩或要求低延迟的场景 (如 Serverless、微服务快速扩容),这一特性具有极其重要的价值。
# 未来展望:生态持续完善
随着 OpenJDK 对 CRaC 项目的持续推进和标准化,以及越来越多第三方库、框架(如 Spring、Micronaut、Quarkus、Open Liberty 等)的积极适配与集成,CRaC 的生态系统正逐步成熟和完善。这预示着未来在 Java 应用中利用 Checkpoint/Restore 技术将变得更加便捷和普遍,有望成为提升 Java 应用启动性能和运行时效率的标准实践之一。
# 六、Apusic JDK with CRaC Support
Apusic JDK 是金蝶天燕(Apusic)公司基于 OpenJDK 项目构建和维护的 Java 开发工具包(JDK)发行版。为了满足用户对高性能和快速启动的需求,Apusic JDK 团队积极跟进社区前沿技术,并提供了对主流 LTS 版本的广泛支持。
-
基于 BiSheng JDK Apusic JDK 的上游是华为公司开源的 BiSheng JDK。BiSheng JDK 本身在 OpenJDK 的基础上进行了性能优化和特性增强,Apusic JDK 继承了这些优势,并结合自身在中间件领域的深厚积累,为企业级应用提供了稳定、高效的 Java 运行时环境。
-
支持多 LTS 版本 Apusic JDK 致力于提供稳定可靠的 Java 环境,目前为 Java 8, 11, 17, 21 等多个长期支持(LTS)版本提供构建和支持。
-
为 JDK 17 和 21 引入 CRaC 支持 Apusic 团队认识到 CRaC(Coordinated Restore at Checkpoint)技术在解决 Java 应用冷启动慢和提升运行时效率方面具有巨大潜力。然而,由于 CRaC 项目尚未正式合并到 OpenJDK 主线,Apusic 采用了与 Azul 等厂商类似的方式,主动将其核心功能移植(Port)并集成到了 Apusic JDK 17 和 Apusic JDK 21 发行版中。
-
提供特定版本的双重发行版 为了方便用户根据实际需求进行选择,针对集成了 CRaC 功能的 JDK 17 和 JDK 21,Apusic 提供了两种发行版:
- 标准的 Apusic JDK (17 / 21) :不包含 CRaC 功能,适用于不需要 Checkpoint/Restore 特性的标准 Java 应用场景。
- Apusic JDK with CRaC Support (17 / 21) :内置了 CRaC 功能的特殊版本。用户可以使用这个版本来开发、测试和部署需要利用 CRaC 进行启动优化的 Java 应用程序。
通过提供带有 CRaC 支持的 JDK 版本(目前为 JDK 17 和 21),Apusic 使得其用户能够在其熟悉的 JDK 发行版上,提前体验和应用 CRaC 技术带来的显著优势,特别是在微服务、Serverless 等对启动速度有严苛要求的场景下,能够获得明显的性能提升。用户在使用 Apusic JDK with CRaC Support 时,可以遵循 CRaC 的标准使用方法和最佳实践。